 Các kiểu dữ liệu trong C ( int - float - double - char ...)
Các kiểu dữ liệu trong C ( int - float - double - char ...)  Thuật toán tìm ước chung lớn nhất trong C/C++
Thuật toán tìm ước chung lớn nhất trong C/C++  Cấu trúc lệnh switch case trong C++ (có bài tập thực hành)
Cấu trúc lệnh switch case trong C++ (có bài tập thực hành)  ComboBox - ListBox trong lập trình C# winforms
ComboBox - ListBox trong lập trình C# winforms  Random trong Python: Tạo số random ngẫu nhiên
Random trong Python: Tạo số random ngẫu nhiên  Lệnh cin và cout trong C++
Lệnh cin và cout trong C++  Cách khai báo biến trong PHP, các loại biến thường gặp
Cách khai báo biến trong PHP, các loại biến thường gặp  Download và cài đặt Vertrigo Server
Download và cài đặt Vertrigo Server  Thẻ li trong HTML
Thẻ li trong HTML  Thẻ article trong HTML5
Thẻ article trong HTML5  Cấu trúc HTML5: Cách tạo template HTML5 đầu tiên
Cấu trúc HTML5: Cách tạo template HTML5 đầu tiên  Cách dùng thẻ img trong HTML và các thuộc tính của img
Cách dùng thẻ img trong HTML và các thuộc tính của img  Thẻ a trong HTML và các thuộc tính của thẻ a thường dùng
Thẻ a trong HTML và các thuộc tính của thẻ a thường dùng Thông báo: Download 4 khóa học Python từ cơ bản đến nâng cao tại đây.
Tìm hiểu Series, DataFrame và Index trong Pandas
Trong bài trước ta đã tìm hiểu về pandas cũng như cách cài đặt thư viện này, vậy thì trong bài này ta sẽ tìm hiểu về Pandas Object, một kiến thức quan trọng khi học Pandas.

Ở mức độ cơ bản nhất thì bạn có thể hiểu Pandas object giống như phiên bản nâng cấp của NumPy Structured Array (bài cuối cùng trong chương NumPy), trong đó các hàng và cột được xác định bằng nhãn (label) thay vì bằng các số nguyên như chỉ mục truyền thống.
Trong bài này, chúng ta sẽ cùng nhau tìm hiểu ba kiểu cấu trúc dữ liệu của Pandas: Series, DataFrame và Index.
1. Pandas Series Object
Series trong Pandas có thể hiểu đơn giản chính là mảng một chiều. Nó có thể được tạo từ một mảng đơn giản như sau:
Bài viết này được đăng tại [free tuts .net]
freetuts_views = pd.Series([1232, 3234, 3250, 2222]) freetuts_views
0 1232 1 3234 2 3250 3 2222 dtype: int64
Như ta có thể ở output, Series bao gồm cả mảng dữ liệu và một mảng chỉ mục (index) mà ta có thể truy cập qua 2 thuộc tính values và index.
Với values thì giá trị trả về chính là một mảng NumPy:
freetuts_views.values
array([1232, 3234, 3250, 2222], dtype=int64)
Còn index thì giá trị trả về có kiểu object pd.Index (ta sẽ nói rõ ở chương 3):
freetuts_views.index
RangeIndex(start=0, stop=4, step=1)
Giống như NumPy, dữ liệu có thể được truy cập theo cách truyền thống như sau:
freetuts_views[2]
3250
Hoặc sử dụng array slicing:
freetuts_views[0:3]
0 1232 1 3234 2 3250 dtype: int64
Nhìn chung ta có thể thấy rằng Series trong pandas ngoài việc giống như ndarray trong NumPy được tổng quát hoá thì nó còn tiện dụng hơn khá nhiều.
2. Pandas DataFrame Object
Tiếp theo chúng ta sẽ đến với DataFrame. Giống như Series, ta có thể hiểu đơn giản DataFrame chính là một mảng NumPy 2 chiều hoặc là một kiểu dictionary "đặc biệt" trong Python, ta sẽ nói về từng trường hợp cụ thể để dễ hình dung về object này nhé.
DataFrame là mảng NumPy
Nếu như Series trong NumPy có thể hiểu như mảng 1 chiều với việc hỗ trợ chỉ mục linh hoạt hơn, thì DataFrame chính là Series ở dạng mảng 2 chiều, trong đó DataFrame cho phép truy cập vào hàng (bằng chỉ mục) và vào cột (bằng tên cột) rất linh hoạt.
Để tìm hiểu rõ về cơ chế này, đầu tiên ta sẽ tạo một Series chứa dữ liệu dân số của một số tỉnh / thành phố trên Việt Nam:
population_dict = {'TP.HCM': 8993, 'Hanoi': 8053, 'Lam Dong': 1297, 'Quang Tri': 623}
population = pd.Series(population_dict)
populationTP.HCM 8993 Hanoi 8053 Lam Dong 1297 Quang Tri 623 dtype: int64
Ta tiếp tục tạo thêm 1 series chứa dữ liệu diện tích của các tỉnh / thành phố tương ứng:
area_dict = {'TP.HCM': 2061, 'Hanoi': 3359, 'Lam Dong': 9765, 'Quang Tri': 4746}
area = pd.Series(area_dict)
areaTP.HCM 2061 Hanoi 3359 Lam Dong 9765 Quang Tri 4746 dtype: int64
Sau khi đã có 2 series trên, ta tiến hành tạo một DataFrame với 2 cột "population" và "area" tương ứng:
vietnam = pd.DataFrame({'Dân số': population, 'Diện tích': area})
vietnamDân số Diện tích TP.HCM 8993 2061 Hanoi 8053 3359 Lam Dong 1297 9765 Quang Tri 623 4746
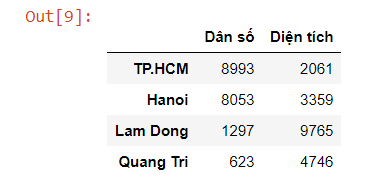
Như trong bài 1 mình đã đề cập, ta có thể DataFrame khá tương tự với Excel, do vậy các bạn sẽ rất dễ làm quen với nó.
Tương tự như Series, DataFrame cũng có thuộc tính index để truy cập vào mảng chỉ mục:
vietnam.index
Index(['TP.HCM', 'Hanoi', 'Lam Dong', 'Quang Tri'], dtype='object')
Thêm vào đó, DataFrame còn có thuộc tính columns, thuộc tính này trả về mảng chứa chỉ mục (nhãn) của từng cột tương ứng:
vietnam.columns
Index(['Dân số', 'Diện tích'], dtype='object')
DataFrame là Dictionary
Tương tự như việc hình dung DataFrame là mảng 2 chiều thì điều đó cũng tương tự với kiểu Dictionary trong Python. Với Dictionary ta có cặp key - value tương ứng thì DataFrame map tên cột với series tương ứng. Ví dụ:
vietnam['Dân số']
TP.HCM 8993 Hanoi 8053 Lam Dong 1297 Quang Tri 623 Name: Dân số, dtype: int64
Và ta có thể lấy dữ liệu như đang thao tác với mảng bình thường bằng 2 cách:
print("Dân số TP.HCM: ", vietnam['Dân số']['TP.HCM'])
print("Dân số TP.HCM: ", vietnam['Dân số'][0])Dân số TP.HCM: 8993 Dân số TP.HCM: 8993
Các cách để tạo DataFrame
Có khá nhiều cách để tạo nên DataFrame, ta sẽ đến với một số cách tạo phổ biến:
Tạo DataFrame từ một series
pd.DataFrame(population, columns=['Dân số'])
Dân số
TP.HCM 8993
Hanoi 8053
Lam Dong 1297
Quang Tri 623Tạo DataFrame từ List của Dictionary
Ta có thể tạo một DataFrame từ List của Dictionary như sau:
data = [{'a': 1, 'b': 2, 'c': 'Freetuts.net'}]
pd.DataFrame(data)a b c 0 1 2 Freetuts.net
Một điều quan trọng là kể cả khi một vài giá trị bị thiếu, pandas vẫn sẽ tạo ra DataFrame cho ta và các giá trị bị thiếu sẽ được điền là NaN (not a number):
pd.DataFrame([{'a': 1, 'b': 2}, {'b': 3, 'c': 'Freetuts.net'}])
a b c
0 1.0 2 NaN
1 NaN 3 Freetuts.netChúng ta sẽ nói về xử lý NaN trong pandas ở các bài sau.
Tạo DataFrame từ một Dictionary chứa các Series
Ta đã nói về cách tạo này ở ví dụ đầu tiên trong phần này. Nếu ta truyền vào một Dictionary thì cặp key - value tương ứng sẽ là cột - series dữ liệu:
vietnam = pd.DataFrame({'Dân số': population, 'Diện tích': area})
vietnam
Dân số Diện tích
TP.HCM 8993 2061
Hanoi 8053 3359
Lam Dong 1297 9765
Quang Tri 623 4746Tạo DataFrame từ mảng 2 chiều NumPy
Với một mảng dữ liệu 2 chiều, ta có thể tạo nên DataFrame đi kèm với tham số columns với giá trị là tên của các cột tương ứng:
pd.DataFrame([[4324, 1242], [6788, 7334]], columns=['Pandas', 'NumPy'])
Pandas NumPy
0 4324 1242
1 6788 7334Ta có thể truyền thêm tham số index để đặt nhãn cho các hàng tương ứng, chẳng hạn:
pd.DataFrame(
[[4324, 1242], [6788, 7334]],
columns=['Pandas', 'NumPy'],
index=['download', 'stars'])
Pandas NumPy
download 4324 1242
stars 6788 7334Tạo DataFrame từ Structured Array của NumPy
Trong chương NumPy ở bài cuối cùng thì mình đã giới thiệu về structured array & module RecordArrays tương ứng. Ta hoàn toàn có thể sử dụng nó để tạo nên một DataFrame trong pandas, ví dụ:
import numpy as np
a = np.ones(3, dtype=[('x', 'i8'), ('y', 'S')])
print("a = ", a)
pd.DataFrame(a)
a = [(1, b'') (1, b'') (1, b'')]
x y
0 1 b''
1 1 b''
2 1 b''3. Pandas Index Object
Sau khi đã tìm hiểu về Series và DataFrame, ta có thể thấy 2 object này đều chứa một thuộc tính là index trong đó nó không phải trả về một mảng bình thường mà là một kiểu dữ liệu riêng biệt, chính vì điều này mà ta có thể thấy index trong pandas là một thuộc tính khá quan trọng.
Bản thân Index object có thể là immutable array (mảng bất biến) hoặc là ordered set (tập hợp sắp thứ tự), do đó có khá nhiều thứ thú vị mà ta có thể làm với Index object, ta sẽ tìm hiểu về các trường hợp cụ thể.
Index là immutable array
Index về cơ bản khá giống với một mảng bình thường, chỉ trừ một điều duy nhất là nó có tính bất biến "immutable" (không thay đổi được giá trị), ví dụ:
ind = pd.Index([1, 2, 4, 7, 10, 12, 15]) ind[2] = 3
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-21-96a8e236cac8> in <module>
1 ind = pd.Index([1, 2, 4, 7, 10, 12, 15])
----> 2 ind[2] = 3
~\anaconda3\lib\site-packages\pandas\core\indexes\base.py in __setitem__(self, key, value)
4079
4080 def __setitem__(self, key, value):
-> 4081 raise TypeError("Index does not support mutable operations")
4082
4083 def __getitem__(self, key):
TypeError: Index does not support mutable operationsMục đích của việc để tính bất biến cho mảng Index chính là nhằm đảm bảo an toàn Còn lại nhìn chung thì nó có hầu hết các đặc điểm của một mảng NumPy, chẳng hạn:
print("Chỉ mục truyền thống: ", ind[0])
print("Array slicing: ", ind[::1])Chỉ mục truyền thống: 1 Array slicing: Int64Index([1, 2, 4, 7, 10, 12, 15], dtype='int64')
Và chứa các thuộc tính của mảng NumPy:
print(ind.size, ind.shape, ind.ndim, ind.dtype)
7 (7,) 1 int64
Index là ordered set
Index object tuân theo nhiều quy ước giống như sets trong Python (vốn tuân theo lý thuyết tập hợp), vậy nên các phép toán như hợp, giao, hiệu và các phép toán khác có thể được dùng như sau:
indexA = pd.Index([1, 2, 3, 5, 7, 9])
indexB = pd.Index([1, 3, 8, 9, 10, 11])
print("Index A: ", indexA)
print("Index B: ", indexB)
print("Giao: ", indexA & indexB)
print("Hiệu: ", indexA - indexB)
print("Hợp: ", indexA | indexB)
print("Hiệu số đối xứng: ", indexA ^ indexB)
print("A <= B and A != B: ", indexA < indexB)
Index A: Int64Index([1, 2, 3, 5, 7, 9], dtype='int64') Index B: Int64Index([1, 3, 8, 9, 10, 11], dtype='int64') Giao: Int64Index([1, 3, 9], dtype='int64') Hiệu: Int64Index([0, -1, -5, -4, -3, -2], dtype='int64') Hợp: Int64Index([1, 2, 3, 5, 7, 8, 9, 10, 11], dtype='int64') Hiệu số đối xứng: Int64Index([2, 5, 7, 8, 10, 11], dtype='int64') A <= B and A != B: [False True True True True True]
4. Tổng kết
Trong bài này chúng ta đã tìm hiểu về 3 object chính trong Pandas - Series, DataFrame và Index. Nhìn chung thì các khái niệm như Series hay DataFrame đều không quá khó hiểu, nó cũng là nền tảng cho toàn bộ series Pandas này.
Trong bài tiếp, chúng ta sẽ tìm hiểu về Data Indexing và Selection nhé, hẹn gặp bạn ở bài tiếp theo.
