 Tinohost
Tinohost  Vultr
Vultr  StableHost
StableHost  HawkHost
HawkHost 
Cách dùng Awk và Regular expression để lọc văn bản file Linux
Trong bài này mình sẽ hướng dẫn cách sử dụng Regular Expression và Awk để lọc văn bản của file trong Linux. Awk là kiến thức nâng cao nên phù hợp với người rành Linux.

Khi mình chạy các lệnh nhất định trong Linux để đọc hoặc chỉnh sửa file, mình thường cố gắng lấy đoạn văn bản mà mình quan tâm nhất. Đây là lúc việc sử dụng Regular Expression và awk trở nên hữu ích.
Và để đọc và hiểu được bài này thì bạn phải có một chút kiến thức về quản trị Linux nhé, vì mọi dòng lệnh đều được thực hiện trên Terminal.
I. Regular Expression là gì?
Regular Expression có thể được định nghĩa như là đại diện của một vài kí tự đặc biệt. Và một trong những điều quan trọng nhất khi nói về Regular Expression là nó cho phép lọc output của câu lệnh hoặc trong một file, có thể chỉnh sửa như là một phần của đoạn văn bản hoặc file cấu hình.
Bài viết này được đăng tại [free tuts .net]
Không chỉ có ở Linux, khái niệm RegExp được sử dụng ở hầu hết các ngôn ngữ lập trình hiện nay, bởi nó là một module được cài vào trình biên dịch của các ngôn ngữ đó.
II. Các tính năng của Regular Expression trong Linux
Những thành phần cấu tạo lên:
Kí tự bình thường: như là khoảng cách, gạch dưới ( _ ), A-Z, a-z, 0-9.
Kí tự meta: là một phần mở rộng của ký tự bình thường.
- ( . ) khớp với bất kì kí tự nào trừ khoảng cách.
- ( * ) khớp với không ký tự nào hoặc ký tự đứng ngay trước nó.
- [ character(s) ] khớp với khoảng chỉ định trong character(s), người ta có thể sử dụng dấu ( - ) như một khoảng ký tự như từ a đến z (a - z ) hoặc từ 0 đến 5 ( 0 - 5).
- ( ^ ) khớp với đoạn đầu của dòng.
- ( $ ) khớp với đoạn cuối của dòng.
- ( \ ) khớp với kí tự escape
Lý thuyết thì sẽ hơi khó hiểu một chút nhưng mình sẽ giải thích chi tiết ở dưới.
Để lọc văn bản, chúng ta phải sử dụng công cụ lọc văn bản như awk , bạn có thể hình dung awk như một ngôn ngữ lập trình của chính nó. Nhưng trong phạm vi bài hướng dẫn này, chúng tôi sẽ đề cập đến nó như một câu lệnh command line đơn giản.
Cú pháp chung của awk là:
awk 'script' filename
Trong đó script là một trong những câu lệnh của awk chúng được dùng để thực thi câu lệnh (execute) trong file đó.
Nó hoạt động bằng cách đọc dòng hiện tại copy dòng đó và thực hiện các câu lệnh trên dòng mới. Nó lặp đi lặp lại trên tất cả các dòng của file.
Script là dạng regular expression awk sẽ tìm tất cả các dạng pattern được tìm thấy trong file.
III. Cách sử dụng công cụ lọc Awk
Như các ví dụ trên, chúng ta sẽ tập trung vào các kí tự meta mà chúng ta đề cập.
Ví dụ đơn giản khi sử dụng awk
Ví dụ ở dưới ta sẽ in tất cả câu dòng trong file /etc/hosts .
awk '//{print}' /etc/hosts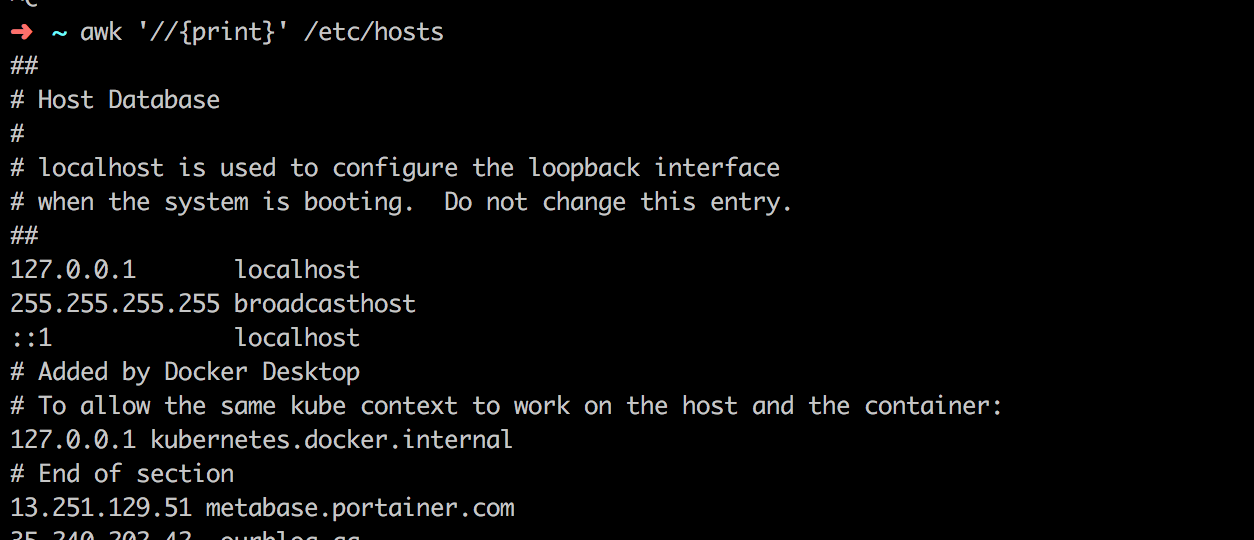
In ra các dòng có khớp với pattern /localhost/
awk '/localhost/{print}' /etc/hosts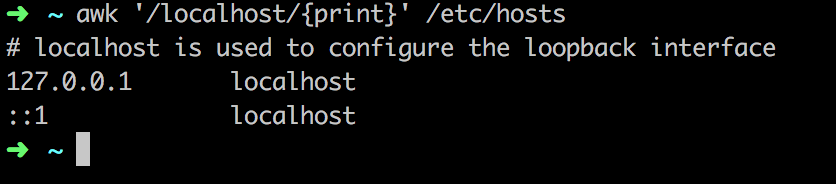
Sử dụng awk cùng với kí tự meta ( . ) trong pattern
Kí tự ( . ) nó sẽ khớp với các chuỗi chứa loc, localhost, nó sẽ như là đại diện cho một ký tự bất kì mà không phải khoảng cách.
awk '/l.c/{print}' /etc/hosts
Sử dụng ký tự meta ( * ) trong pattern
pattern dưới nó sẽ khớp với toàn bộ ký tự chứa localhost,...
awk '/l*c/{print}' /etc/hosts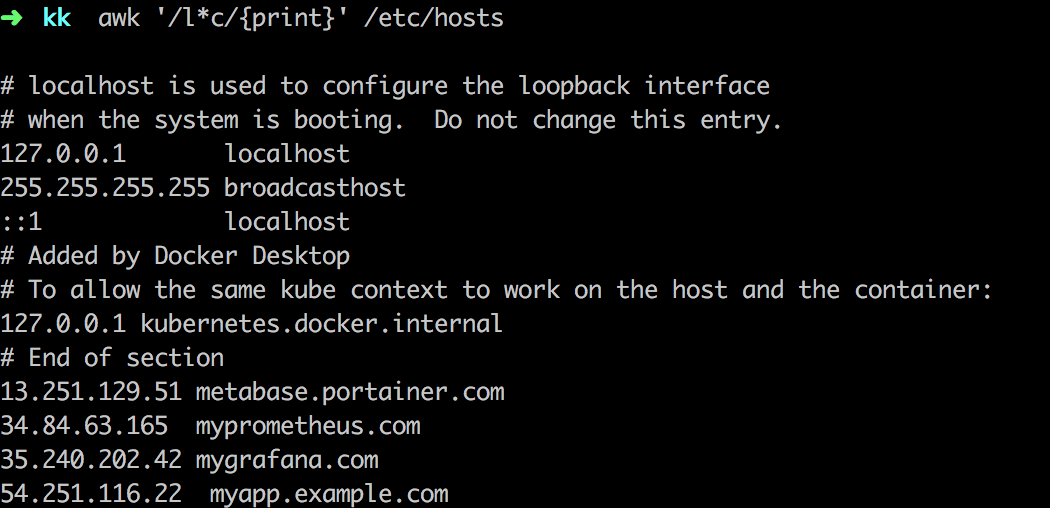
Bạn có thể nhận ra rằng kí tự meta ( * ) cố gắng lấy được đoạn dài nhất mà khớp với pattern /l*c/
Hãy nhìn vào trường hợp sau đây để chứng minh điều đó, pattern /t*t/ nghĩa là bắt đầu bằng chữ t và kết thúc bằng chữ t trong ví dụ sau:

Có rất nhiều đoạn match với bắt đầu bằng chữ t và kết thúc bằng chữ t:
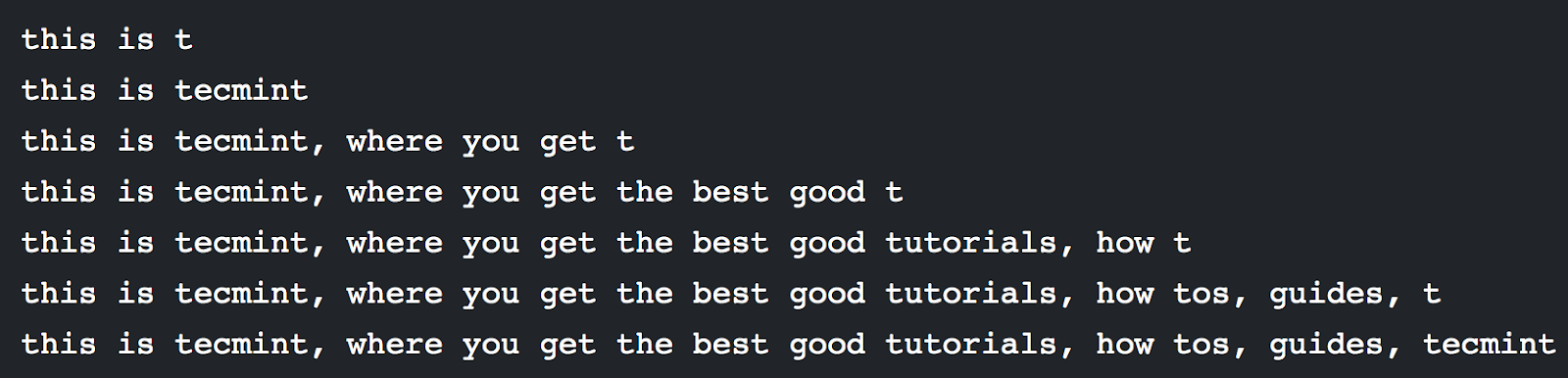
Nhưng với awk ta sẽ lấy đoạn dài nhất, ta có câu lệnh:
awk '/t*t/{print}' test.txt
Sử dụng awk với [ character(s) ]
Ta lấy một ví dụ như pattern /[9p]/. Awk sẽ khớp với tất cả ký tự nào có chứa 9 hoặc là p trong file /etc/hosts
awk '/[9p]/{print}' /etc/hosts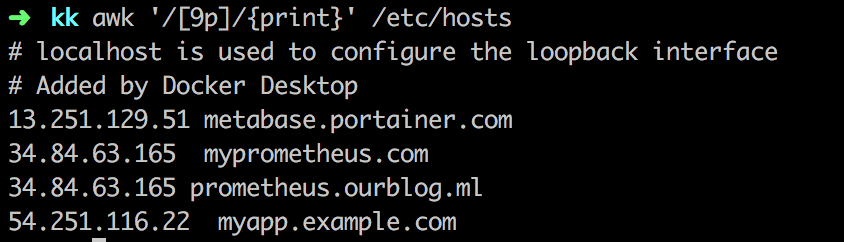
Ở ví dụ tiếp theo ta sẽ bắt đầu bằng một ký tự p hoặc là ký tự g tiếp theo là ký tự r
awk '/[pg]r/{print}' /etc/hosts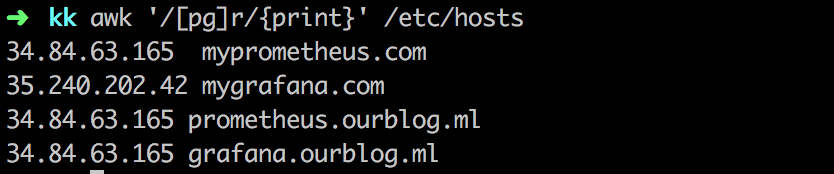
Chỉ định các ký tự nằm trong một phạm vi
Và trước hết ta phải hiểu một vài khoảng hay dùng trong awk:
- [0-9]: nghĩa là một số duy nhất
- [a-z]: nghĩa là một chữ cái viết thường
- [A-Z]: nghĩa là một chữ cái viết hoa
- [a-zA-Z]: nghĩa là một chữ cái không phân biệt hoa thường
- [a-zA-Z0-9]: nghĩa là một chữ cái không phân biệt hoa thường hoặc là một số nào đó
Một vài ví dụ minh hoạ:
awk '/[0-9]/{print}' /etc/hosts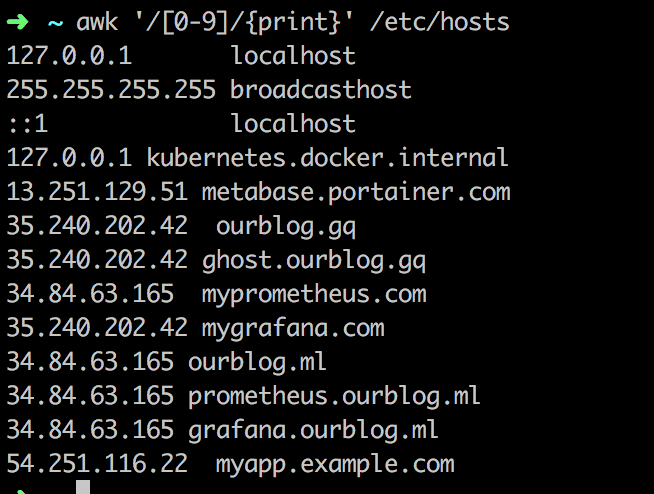
Tất cả các dòng trong file /etc/hosts chứa ít nhất là một số từ 0 đến 9 đều được in ra.
Sử dụng awk cùng với ký tự ( ^ )
Ta bắt đầu bằng với pattern đơn giản sau:
awk '/^13/{print}' /etc/hostsNó sẽ match tất cả cả dòng bắt đầu bằng ký tự 13

Sử dụng awk cùng với ký tự ( $ )
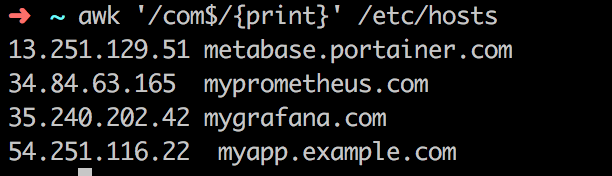
ta cũng bắt đầu bằng pattern sau để hiểu rõ hơn.
awk '/com$/{print}' /etc/hostsTa sẽ tìm tất cả các dòng sao cho ký tự cuối là com
Sử dụng awk cùng với ký tự escape ( \ )
Ký tự ( \ ) được sử dụng khi bạn muốn tìm ra những ký tự nhưng mà ký tự ấy lại bao gồm những ký tự meta. Ví dụ bạn muốn tìm ra đoạn có ký tự “ $25 “. ví dụ:
Mình có file escape.txt như sau:
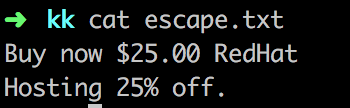
awk '/$25.00/{print}' escape.txt # =>> không tìm được
awk '/\$25.00/{print}' escape.txt # =>> tìm được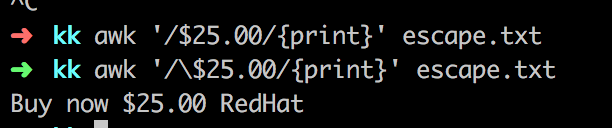
các bạn có thể cùng thực hành bằng các file trong git như sau: https://github.com/AnTienTL/awk-learning
Tổng kết
Qua những ví dụ trên ta đã tìm hiểu được căn bản về awk. Những bài sau mình sẽ giới thiệu về những tính năng xịn sò của awk và những trường hợp nào nên dùng. Cảm ơn các bạn đã đọc.

