Các kiểu dữ liệu trong C ( int - float - double - char ...)
Các kiểu dữ liệu trong C ( int - float - double - char ...)  Thuật toán tìm ước chung lớn nhất trong C/C++
Thuật toán tìm ước chung lớn nhất trong C/C++  Cấu trúc lệnh switch case trong C++ (có bài tập thực hành)
Cấu trúc lệnh switch case trong C++ (có bài tập thực hành)  ComboBox - ListBox trong lập trình C# winforms
ComboBox - ListBox trong lập trình C# winforms  Random trong Python: Tạo số random ngẫu nhiên
Random trong Python: Tạo số random ngẫu nhiên  Lệnh cin và cout trong C++
Lệnh cin và cout trong C++  Cách khai báo biến trong PHP, các loại biến thường gặp
Cách khai báo biến trong PHP, các loại biến thường gặp  Download và cài đặt Vertrigo Server
Download và cài đặt Vertrigo Server  Thẻ li trong HTML
Thẻ li trong HTML  Thẻ article trong HTML5
Thẻ article trong HTML5  Cấu trúc HTML5: Cách tạo template HTML5 đầu tiên
Cấu trúc HTML5: Cách tạo template HTML5 đầu tiên  Cách dùng thẻ img trong HTML và các thuộc tính của img
Cách dùng thẻ img trong HTML và các thuộc tính của img  Thẻ a trong HTML và các thuộc tính của thẻ a thường dùng
Thẻ a trong HTML và các thuộc tính của thẻ a thường dùng Cấu trúc dữ liệu của danh sách liên kết đơn
Trong hướng dẫn này mình sẽ giới thiệu đến các bạn danh sách liên kết đơn là gì, cũng như cấu trúc dữ liệu của nó và cách khai báo danh sách.

Danh sách liên kết đơn là loại DSLK đơn giản và dễ cài đặt nhất trong 3 loại mà chúng ta sẽ học trong series cấu trúc dữ liệu. Để hiểu được nó thì bạn phải có kiến thức nền tảng C++ hoặc C nhé.
1. Danh sách liên kết đơn là gì?
Danh sách liên kết đơn là một cấu trúc dữ liệu động sử dụng con trỏ để cài đặt và trỏ đến các phần tử trong danh sách.
Trong DSLK đơn thì mỗi phần tử sẽ liên kết với phần tử đứng sau nó trong danh sách, ta gọi là các phần tử đó là Node. Mỗi node có hai thông số cần quan tâm, đó là:
Bài viết này được đăng tại [free tuts .net]
- Giá trị (data)
- Mối liên kết tới node khác (pNext).
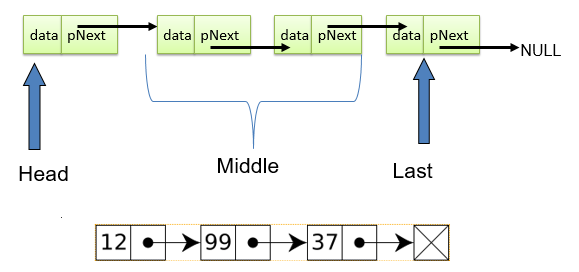
Như hình trên, ở node thứ hai có liên kết với node thứ nhất thông qua pNext, tương tự như vậy node thứ ba liên kết với node thứ hai cũng thông qua pNext.
2. Cấu trúc dữ liệu của DSLK đơn – quản lý bằng pHead
Trong danh sách liên kết đơn ta có mỗi phần tử liên kết với phần tử đứng sau nó trong danh sách. Mỗi phần tử gồm một Node và mỗi Node có hai thông tin: Giá trị (data) và con trỏ pNext trỏ tới phần tử kế tiếp.
Ở phần này chúng ta sẽ quản lý danh sách liên kết bằng 1 con trỏ pHead (trỏ tới phần tử đầu).
Ví dụ: ta có một danh sách liên kết đơn sử dụng pHead để quản lý
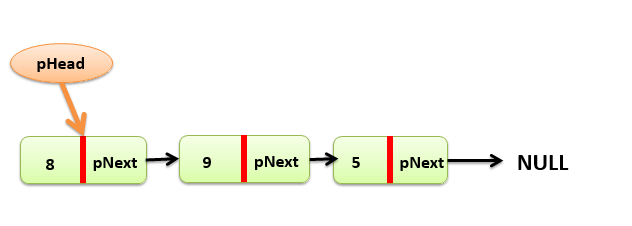
Trong danh sách ta cần xác định các thông tin sau:
- pHead là Node đầu của danh sách liên kết đơn.
- Các giá trị 8, 9, 5 phía bên trái gạch đỏ là giá trị (data) của Node.
- pNext là con trỏ, trỏ đến phần tử sau.
Dựa vào các thông tin trên, ta có cấu trúc dữ liệu sử dụng pHead để quản lý:
/* Khai báo giá trị data và con trỏ pNext trỏ tới phần tử kế tiếp */
struct Node
{
int data;// giá trị data của node
Node *pNext;// con trỏ pNext
};
/* Khai báo Node đầu pHead */
struct SingleList
{
Node *pHead; //Node đầu pHead
};
/* khởi tạo giá trị cho Node */
void Initialize(SingleList &list)
{
list.pHead=NULL;// khởi tạo giá trị cho Node là Null
}
Như vậy là chúng ta đã khai báo các thông tin có trong một danh sách liên kết đơn sử dụng pHead để quản lý.
3. Cấu trúc dữ liệu của DSLK đơn – quản lý bằng pHead và pTail
Về cơ bản việc sử dụng pHead và pTail để quản lý DSLK đơn tương tự như việc sử dụng pHead. Tuy nhiên khi chúng ta sử dụng pHead và pTail thì việc insertLast() sẽ rất thuận tiện và dễ dàng.
Minh họa danh sách liên kết đơn sử dụng 2 con trỏ pHead và pTail. pHead luôn luôn quản lý node đầu, pTail luôn luôn quản lý node cuối.
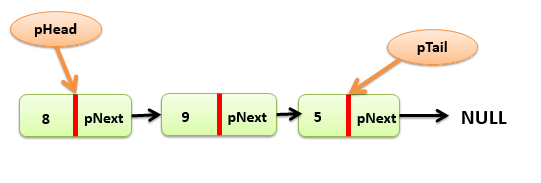
Ta có pHead quản lý Node đầu và pTail quản lý Node cuối, vì vậy khi khai báo ở cấu trúc SingleList() chúng ta sẽ khai báo cả pHead và pTail.
/* Khai báo Node đầu pHead và Node cuối pTail*/
struct SingleList
{
Node *pHead; //Node đầu pHead
Node *pTail; // Node cuối pTail
};
Cũng như khi khởi tạo giá trị, thì chúng ta sẽ phải khởi tạo cho cả pHead và pTail bằng Null.
void Initialize(SingleList &list)
{
list.pHead=list.pTail=NULL;// khởi tạo giá trị cho Node đầu và Node cuối là Null
}
Full code: cấu trúc dữ liệu trong DSLK đơn
/* Khai báo giá trị data và con trỏ pNext trỏ tới phần tử kế tiếp */
struct Node
{
int data;// giá trị data của node
Node *pNext;// con trỏ pNext
};
/* Khai báo Node đầu pHead và Node cuối pTail*/
struct SingleList
{
Node *pHead; //Node đầu pHead
Node *pTail; // Node cuối pTail
};
/* khởi tạo giá trị cho Node đầu và Node cuối */
void Initialize(SingleList &list)
{
list.pHead=list.pTail=NULL;// khởi tạo giá trị cho Node đầu và Node cuối là Null
}
Việc sử dụng pHead và pTail có ưu điểm là không cần phải duyệt DSLk khi insertLast, nhưng bù lại nhược điểm của nó sẽ tốn bộ nhớ để khởi tạo biến pTail. Vì vậy các bạn hãy điều chỉnh việc sử dụng hai cách quản lý này cho phù hợp với bài toán.
Kết luận
Trong bài viết này mình đã giới thiệu về danh sách liên kết đơn và cấu trúc dữ liệu của nó. Ở bài tiếp theo chúng ta sẽ cùng nhau thực hiện tạo Node trong danh sách liên kết đơn. Các bạn hãy chú ý theo dõi nhé.