 Các kiểu dữ liệu trong C ( int - float - double - char ...)
Các kiểu dữ liệu trong C ( int - float - double - char ...)  Thuật toán tìm ước chung lớn nhất trong C/C++
Thuật toán tìm ước chung lớn nhất trong C/C++  Cấu trúc lệnh switch case trong C++ (có bài tập thực hành)
Cấu trúc lệnh switch case trong C++ (có bài tập thực hành)  ComboBox - ListBox trong lập trình C# winforms
ComboBox - ListBox trong lập trình C# winforms  Random trong Python: Tạo số random ngẫu nhiên
Random trong Python: Tạo số random ngẫu nhiên  Lệnh cin và cout trong C++
Lệnh cin và cout trong C++  Cách khai báo biến trong PHP, các loại biến thường gặp
Cách khai báo biến trong PHP, các loại biến thường gặp  Download và cài đặt Vertrigo Server
Download và cài đặt Vertrigo Server  Thẻ li trong HTML
Thẻ li trong HTML  Thẻ article trong HTML5
Thẻ article trong HTML5  Cấu trúc HTML5: Cách tạo template HTML5 đầu tiên
Cấu trúc HTML5: Cách tạo template HTML5 đầu tiên  Cách dùng thẻ img trong HTML và các thuộc tính của img
Cách dùng thẻ img trong HTML và các thuộc tính của img  Thẻ a trong HTML và các thuộc tính của thẻ a thường dùng
Thẻ a trong HTML và các thuộc tính của thẻ a thường dùng Thông báo: Download 4 khóa học Python từ cơ bản đến nâng cao tại đây.
Giới thiệu về Graph Machine Learning trong Python
Đây là bài viết giới thiệu cơ bản, giúp bạn làm quen với các thuật ngữ cơ bản của lĩnh vực Học Máy trên Đồ Thị (Graph Machine Learning - Graph ML). Trong các phần tiếp theo, chúng ta sẽ đi sâu vào các khía cạnh chi tiết của Graph ML, cùng với những trải nghiệm thực tế khi sử dụng các mạng nơ-ron đồ thị (Graph Neural Networks) trong thư viện PyTorch Geometric hoặc DGL.

Tại sao Graph ML ngày càng phổ biến?
Các kỹ thuật học máy truyền thống, như hồi quy tuyến tính, Naive Bayes, cây quyết định, rừng ngẫu nhiên (Random Forest), SVM, SVR, vốn là sự kết hợp giữa suy luận thống kê và các thuật toán tính toán, đã hoạt động rất hiệu quả trên những loại dữ liệu có độ phức tạp thấp.
Tuy nhiên, khi dữ liệu ngày càng phức tạp hơn cả về cấu trúc lẫn độ chiều (ví dụ: hình ảnh, văn bản, sóng tín hiệu, đồ thị...), các thuật toán này bắt đầu gặp khó khăn. Những vấn đề phổ biến như lời nguyền của chiều không gian (curse of dimensionality), hiện tượng underfitting hoặc overfitting xuất hiện thường xuyên hơn.
Khi các thuật toán truyền thống không còn đáp ứng được độ phức tạp của dữ liệu, một nhánh mới của học máy là Học Sâu (Deep Learning) đã ra đời. Tất cả các thuật toán học sâu, từ cơ bản đến phức tạp, đều dựa trên nền tảng của Mạng Nơ-ron (Neural Networks). Dựa vào cơ chế hoạt động của mạng nơ-ron, các kiến trúc cơ bản như CNN (mạng tích chập) cho dữ liệu hình ảnh và RNN (mạng hồi quy) cho dữ liệu chuỗi lần lượt được phát triển. Chúng giúp học và khái quát hóa các hàm gần đúng phức tạp cho dữ liệu như hình ảnh, văn bản, sóng tín hiệu.
Bài viết này được đăng tại [free tuts .net]
Tuy nhiên, tất cả các phương pháp trên chủ yếu áp dụng cho dữ liệu có cấu trúc (structured data), ví dụ: bảng dữ liệu, hình ảnh, văn bản, đều thuộc dạng dữ liệu Euclidean. Tính chất Euclidean này giúp việc học và tối ưu hóa dễ dàng hơn.
Nhưng đối với dữ liệu đồ thị (graphical data), vấn đề trở nên phức tạp hơn. Dữ liệu đồ thị xuất hiện ở khắp nơi trong thế giới thực, ví dụ:
- Mạng internet
- Mạng xã hội (kết nối bạn bè trên Facebook)
- Cấu trúc phân tử
- Não bộ con người (kết nối hàng triệu neuron)
- Hình khối 3D
Ngay cả hình ảnh, văn bản, hoặc sóng tín hiệu cũng có thể được biểu diễn dưới dạng đồ thị, nhưng những dạng này thuộc loại đồ thị có cấu trúc, không giống như các đồ thị tổng quát.
Dữ liệu đồ thị mang tính phi Euclidean (non-Euclidean), không có chiều dài hoặc hình dạng cụ thể. Điều này làm cho các mô hình học sâu truyền thống khó học được cấu trúc của đồ thị.
Ví dụ, bạn có thể dùng ma trận kề (adjacency matrix) để biểu diễn kết nối trong đồ thị, nhưng nếu dữ liệu lớn như mạng xã hội Facebook, ma trận này sẽ rất thưa thớt (sparse) và gây lãng phí tài nguyên tính toán. Vì vậy, cần một phương pháp mới để tối ưu và học từ dữ liệu đồ thị: Học Máy trên Đồ Thị (Graph Machine Learning).
Đồ thị là gì?
Đồ thị là một tập hợp các đỉnh (nodes) được kết nối bởi các cạnh (edges). Về mặt toán học, đồ thị được định nghĩa như sau:
Trong đó:
- : đồ thị
- : tập hợp các đỉnh
- : tập hợp các cạnh
- : ma trận kề biểu diễn cấu trúc kết nối.
Node Features (Đặc trưng đỉnh)
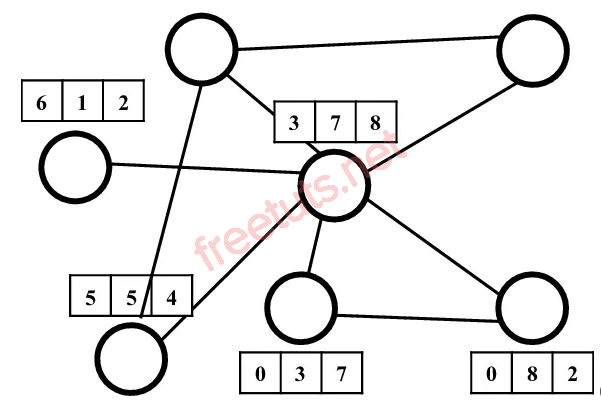
Trong học máy, các đỉnh không chỉ đơn thuần là các số (1, 2, 3...) hay ký tự (A, B, C...), mà mỗi đỉnh thường mang một vector đặc trưng (feature vector). Ví dụ, trong đồ thị phân tử:
Các đỉnh là các nguyên tử.
Vector đặc trưng của mỗi nguyên tử có thể gồm:
- Số hiệu nguyên tử
- Số khối
- Kiểu lai hóa (hybridization)
Tập hợp các vector đặc trưng của đỉnh tạo thành một ma trận kích thước , trong đó là số đỉnh và là số chiều của vector đặc trưng.
Edge Features (Đặc trưng cạnh)
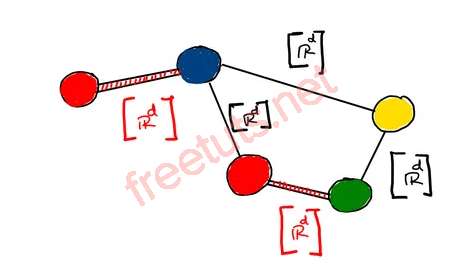
Tương tự, các cạnh cũng có thể mang đặc trưng riêng, nhưng cần lưu ý rằng đặc trưng cạnh không đại diện cho kết nối giữa các đỉnh. Kết nối được biểu diễn thông qua ma trận kề (adjacency matrix).
Ví dụ, trong đồ thị phân tử, các cạnh là các liên kết hóa học:
- Loại liên kết (đơn, đôi, ba...)
- Góc liên kết
- Tính chất hóa học khác
Những đặc trưng này được ghép lại thành vector chiều, gọi là vector đặc trưng cạnh. Tuy nhiên, không phải lúc nào đặc trưng cạnh cũng quan trọng bằng đặc trưng đỉnh.
Ma trận kề và danh sách kề
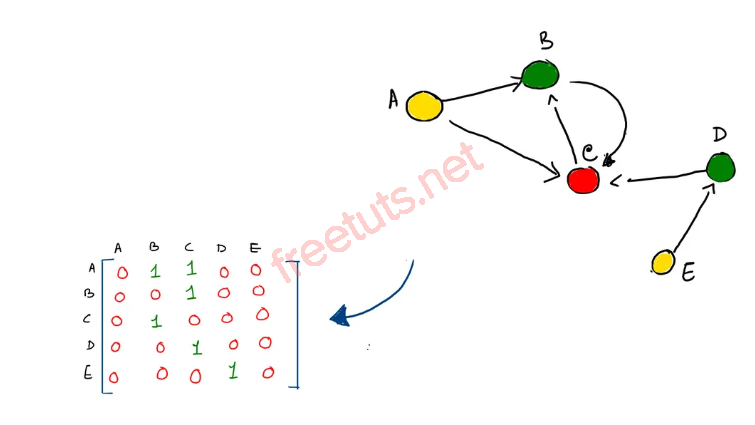
Ma trận kề là cách lưu trữ kết nối giữa các đỉnh, với giá trị 1 biểu thị có kết nối và 0 biểu thị không kết nối. Tuy nhiên, với đồ thị lớn (như mạng xã hội), ma trận kề thường rất thưa thớt.
Để tối ưu, có thể sử dụng danh sách kề (adjacency list) hoặc định dạng tọa độ (COO), biểu diễn kết nối dưới dạng các cặp (source, target).
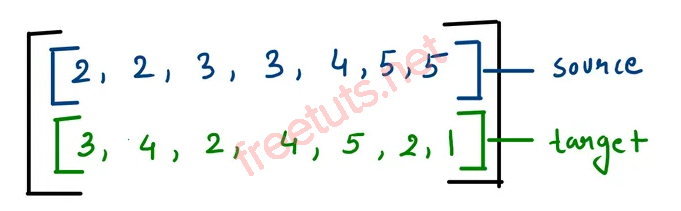
Embedding (Biểu diễn nhúng)
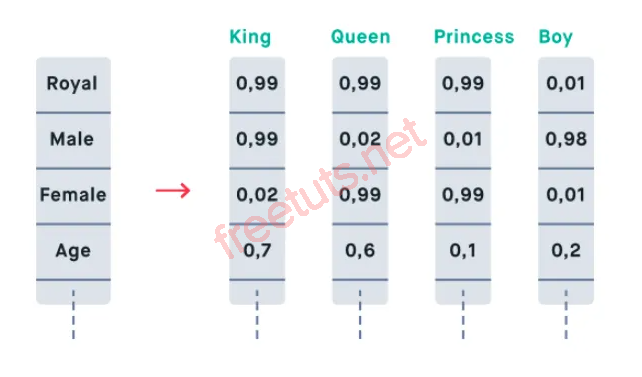
Embedding là cách biểu diễn dữ liệu từ không gian cao chiều về không gian thấp chiều, sao cho các đặc trưng quan trọng được giữ lại. Trong đồ thị, nhúng có thể áp dụng cho:
- Đỉnh (node embedding): Biểu diễn vector đặc trưng của các đỉnh sao cho các đỉnh giống nhau được nhóm gần nhau.
- Đồ thị (graph embedding): Biểu diễn đặc trưng tổng thể của đồ thị dựa trên đặc trưng của các đỉnh/cạnh.
Quy trình giải quyết bài toán Graph ML
- Thu thập dữ liệu thô.
- Xây dựng bài toán dưới dạng bài toán đồ thị.
- Chuyển dữ liệu thô thành dữ liệu đồ thị (đỉnh và cạnh có ý nghĩa).
- Áp dụng các phương pháp Graph ML để trích xuất biểu diễn có ý nghĩa.
- Thực hiện các nhiệm vụ cần thiết.
- Triển khai mô hình đã huấn luyện.
Ứng dụng của Graph ML
- Phát hiện thuốc.
- Sinh lưới 2D, 3D (Mesh generation).
- Dự đoán tính chất phân tử.
- Xác định vòng kết nối xã hội.
- Hệ thống gợi ý thế hệ mới.
- Dự báo giao thông.
- Hoàn thiện đồ thị tri thức.
Kết bài
Qua bài viết này, bạn đã hiểu vì sao Graph ML trở nên quan trọng, cùng các khái niệm và thuật ngữ cơ bản. Ở các phần tiếp theo, chúng ta sẽ khám phá các loại đồ thị, bài toán trong Graph ML, và cách xây dựng mô hình bằng PyTorch Geometric hoặc DGL. Hãy đón chờ nhé!
