 Các kiểu dữ liệu trong C ( int - float - double - char ...)
Các kiểu dữ liệu trong C ( int - float - double - char ...)  Thuật toán tìm ước chung lớn nhất trong C/C++
Thuật toán tìm ước chung lớn nhất trong C/C++  Cấu trúc lệnh switch case trong C++ (có bài tập thực hành)
Cấu trúc lệnh switch case trong C++ (có bài tập thực hành)  ComboBox - ListBox trong lập trình C# winforms
ComboBox - ListBox trong lập trình C# winforms  Random trong Python: Tạo số random ngẫu nhiên
Random trong Python: Tạo số random ngẫu nhiên  Lệnh cin và cout trong C++
Lệnh cin và cout trong C++  Cách khai báo biến trong PHP, các loại biến thường gặp
Cách khai báo biến trong PHP, các loại biến thường gặp  Download và cài đặt Vertrigo Server
Download và cài đặt Vertrigo Server  Thẻ li trong HTML
Thẻ li trong HTML  Thẻ article trong HTML5
Thẻ article trong HTML5  Cấu trúc HTML5: Cách tạo template HTML5 đầu tiên
Cấu trúc HTML5: Cách tạo template HTML5 đầu tiên  Cách dùng thẻ img trong HTML và các thuộc tính của img
Cách dùng thẻ img trong HTML và các thuộc tính của img  Thẻ a trong HTML và các thuộc tính của thẻ a thường dùng
Thẻ a trong HTML và các thuộc tính của thẻ a thường dùng Thông báo: Download 4 khóa học Python từ cơ bản đến nâng cao tại đây.
Top 4 thư viện phổ biến nhất của NLP trong Python
Xử lý ngôn ngữ tự nhiên (NLP) đóng vai trò quan trọng trong nhiều lĩnh vực, từ công nghiệp đến nghiên cứu và giáo dục. NLP giúp máy tính hiểu và tương tác với ngôn ngữ tự nhiên của con người, mở ra nhiều ứng dụng hứa hẹn như chatbot, dịch máy, phân tích cảm xúc, và nhiều hơn nữa. Trong cộng đồng lập trình Python, có một loạt các thư viện và framework phổ biến được sử dụng để thực hiện các tác vụ NLP. Trong bài viết này, chúng ta sẽ tìm hiểu về top 4 thư viện phổ biến nhất của NLP trong Python và cách chúng được sử dụng trong các ứng dụng thực tế.

Xử lý ngôn ngữ tự nhiên (NLP) là gì?
.jpg)
Xử lý ngôn ngữ tự nhiên (NLP) là một lĩnh vực của trí tuệ nhân tạo (AI) tập trung vào tương tác giữa máy tính và ngôn ngữ tự nhiên của con người. Mục tiêu của NLP là phân tích, hiểu, và tạo ra các công cụ để làm việc với ngôn ngữ tự nhiên một cách tự động và hiệu quả. Các nhiệm vụ trong NLP có thể bao gồm nhận dạng ngôn ngữ, dịch máy, phân tích cú pháp, trích xuất thông tin, tổng hợp văn bản, và nhiều hơn nữa. NLP được áp dụng rộng rãi trong nhiều lĩnh vực, bao gồm công nghiệp, y tế, tư pháp, giáo dục, và truyền thông.
Ứng dụng của NLP trong Python
Ứng dụng của xử lý ngôn ngữ tự nhiên (NLP) trong thế giới thực rất đa dạng và phong phú. Dưới đây là một số ví dụ tiêu biểu:
-
Chatbot và trợ lý ảo: NLP được sử dụng để phát triển các hệ thống trò chuyện tự động, như chatbot và trợ lý ảo, để tương tác với người dùng và cung cấp hỗ trợ tức thì, giải đáp câu hỏi, hoặc thực hiện các nhiệm vụ cụ thể.
Bài viết này được đăng tại [free tuts .net]
-
Dịch máy: Công nghệ NLP cho phép dịch tự động giữa các ngôn ngữ khác nhau, giúp người dùng truy cập thông tin và nội dung từ các nguồn đa ngôn ngữ một cách thuận tiện.
-
Phân tích cảm xúc và phản hồi của người dùng: NLP được sử dụng để phân tích và hiểu cảm xúc trong văn bản, bài đăng trên mạng xã hội, hoặc phản hồi của khách hàng trong các dịch vụ trực tuyến, từ đó đưa ra phản hồi hoặc giải pháp phù hợp.
-
Tóm tắt và trích xuất thông tin: Công nghệ NLP giúp tự động tóm tắt và trích xuất thông tin quan trọng từ văn bản dài, giúp người dùng tiết kiệm thời gian và công sức trong việc đọc và nắm bắt thông tin.
-
Xử lý ngôn ngữ tự nhiên trong y học: NLP được sử dụng trong các ứng dụng y học để tự động phân tích tài liệu y khoa, báo cáo bệnh án, và giúp đánh giá và dự đoán kết quả của bệnh nhân.
-
Xử lý ngôn ngữ tự nhiên trong tư pháp: Trong lĩnh vực tư pháp, NLP được sử dụng để phân tích và trích xuất thông tin từ các tài liệu pháp luật và văn bản liên quan đến các vụ án.
-
Phân loại văn bản và dữ liệu: NLP được áp dụng để phân loại và phân tích dữ liệu từ các nguồn khác nhau, như email, tin nhắn, hoặc bài đăng trên mạng xã hội, để giúp tổ chức và quản lý thông tin một cách hiệu quả.
Những ứng dụng trên chỉ là một phần nhỏ của những gì mà xử lý ngôn ngữ tự nhiên có thể làm trong thế giới thực. Sự phát triển và ứng dụng của NLP tiếp tục mở ra nhiều cơ hội mới trong nhiều lĩnh vực khác nhau.
SpaCy với NLP trong Python
SpaCy là một thư viện xử lý ngôn ngữ tự nhiên (NLP) mã nguồn mở được phát triển bởi Matthew Honnibal và Ines Montani. SpaCy được thiết kế để xử lý ngôn ngữ tự nhiên một cách nhanh chóng, hiệu quả và dễ dàng sử dụng. SpaCy cung cấp các công cụ để thực hiện các nhiệm vụ NLP như phân tích cú pháp, nhận dạng thực thể, và tách từ.
Tính năng và ứng dụng của SpaCy
- Xử lý văn bản tự nhiên: SpaCy cung cấp các công cụ để xử lý văn bản tự nhiên, bao gồm tách từ, nhận dạng từ loại, phân tích cú pháp, và trích xuất thông tin.
- Hỗ trợ nhiều ngôn ngữ: SpaCy hỗ trợ nhiều ngôn ngữ và cung cấp các mô hình ngôn ngữ đã được huấn luyện sẵn.
- Tốc độ xử lý: SpaCy được tối ưu hóa để hoạt động nhanh chóng và hiệu quả, thích hợp cho việc xử lý các tập dữ liệu lớn.
- Hỗ trợ các tính năng tiên tiến: SpaCy cung cấp các tính năng tiên tiến như trích xuất thực thể và phân tích cú pháp văn bản.
So sánh với NLTK
- So với NLTK (Natural Language Toolkit), SpaCy thường được coi là nhanh hơn và dễ sử dụng hơn.
- SpaCy cung cấp các mô hình ngôn ngữ được huấn luyện sẵn, trong khi NLTK yêu cầu người dùng tự huấn luyện mô hình.
- NLTK chủ yếu được sử dụng cho mục đích giáo dục và nghiên cứu, trong khi SpaCy thường được ứng dụng trong các dự án thực tiễn với quy mô lớn.
Ví dụ minh họa về việc sử dụng SpaCy
import spacy
# Load mô hình ngôn ngữ tiếng Anh
nlp = spacy.load("en_core_web_sm")
# Bài viết này được đăng tại freetuts.net
# Văn bản đầu vào
text = "SpaCy is an awesome NLP library."
# Xử lý văn bản
doc = nlp(text)
# Hiển thị từng từ và từ loại tương ứng
for token in doc:
print(token.text, token.pos_)
Output:
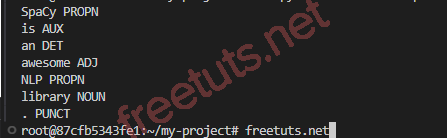
Trong ví dụ này, mình sử dụng SpaCy để tách từ và xác định từ loại (POS) của mỗi từ trong câu.
Gensim với NLP trong Python

Gensim là một thư viện mã nguồn mở trong Python được sử dụng chủ yếu cho xử lý và phân tích văn bản. Gensim tập trung vào việc triển khai các thuật toán học không giám sát, đặc biệt là mô hình vectơ từ và mô hình topic.
Gensim trong xử lý văn bản và phân tích văn bản
- Vectorization: Gensim cung cấp các công cụ để biểu diễn văn bản dưới dạng các vectơ số học, như mô hình vectơ từ (Word2Vec) và Doc2Vec.
- Topic modeling: Gensim hỗ trợ việc thực hiện các mô hình topic như Latent Dirichlet Allocation (LDA), giúp phân tích cấu trúc ý nghĩa của văn bản.
Ví dụ minh họa về việc sử dụng Gensim
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
# Bài viết này được đăng tại freetuts.net
# Dữ liệu văn bản
sentences = [["I", "love", "machine", "learning"],
["Deep", "learning", "is", "awesome"],
["Natural", "language", "processing", "is", "interesting"]]
# Huấn luyện mô hình Word2Vec
model = Word2Vec(sentences, min_count=1)
# Vector của từ "machine"
print("Vector của từ 'machine': ", model.wv['machine'])
# Tìm từ gần nhất với từ "learning"
print("Từ gần nhất với 'learning': ", model.wv.most_similar('learning'))
# Tải mô hình đã huấn luyện trước
# model = KeyedVectors.load_word2vec_format('path/to/pretrained/model.bin', binary=True)
Output:
Vector của từ 'machine': [-1.1998636e-03 -3.4924259e-03 -4.8682327e-03 -1.1383692e-03 3.6783375e-03 -2.4569261e-03 2.0520525e-03 3.6285812e-03 ... 1.3351051e-03 -2.0486790e-03 -4.5683804e-03 1.0360553e-03 2.4489043e-03 -3.7572354e-03 -4.7371574e-03 -4.4145681e-03]
Từ gần nhất với 'learning': [('is', 0.19737508845329285), ('language', 0.14364197874069214), ('I', 0.12678244709968567), ('processing', 0.12642985582351685), ('interesting', 0.082037761449337)]
Trong ví dụ này,mình sử dụng Gensim để huấn luyện một mô hình Word2Vec trên một tập dữ liệu văn bản đơn giản, sau đó sử dụng mô hình này để biểu diễn các từ dưới dạng vectơ số học và tìm từ gần nhất với một từ cho trước.
Transformers (Hugging Face) với NLP trong Python
.jpg)
Transformers là một thư viện mã nguồn mở do Hugging Face phát triển, cung cấp các kiến trúc mô hình tiên tiến trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP). Các kiến trúc mô hình trong Transformers chủ yếu dựa trên các kiến trúc mạng nơ-ron hồi quy tái sinh (RNN) và biến thể của chúng như mạng nơ-ron biến thể tự chú ý (BERT), mạng nơ-ron biến thể tự chú ý sâu (BERT), GPT (Generative Pre-trained Transformer), và nhiều hơn nữa.
Các tính năng của Transformers trong NLP
- Pre-trained models: Transformers cung cấp nhiều mô hình tiền huấn luyện sẵn được huấn luyện trên các tác vụ NLP khác nhau, giúp giảm thiểu thời gian và công sức cần thiết để huấn luyện mô hình mới.
- Fine-tuning: Bằng cách sử dụng các mô hình tiền huấn luyện sẵn, bạn có thể tinh chỉnh chúng trên dữ liệu cụ thể cho một nhiệm vụ cụ thể, như phân loại văn bản, tạo văn bản, hoặc dịch máy.
- State-of-the-art performance: Các mô hình trong Transformers thường đạt được hiệu suất cao trên nhiều tác vụ NLP, vượt trội so với các phương pháp truyền thống.
Ví dụ minh họa về việc sử dụng Transformers
from transformers import pipeline
# Bài viết này được đăng tại freetuts.net
# Tạo pipeline để phân loại văn bản
classifier = pipeline("sentiment-analysis")
# Phân loại cảm xúc của một câu
result = classifier("This movie is really great!")
print(result)
Output:
[{'label': 'POSITIVE', 'score': 0.9998700618743896}]
Trong ví dụ này, mình sử dụng Transformers để tạo một pipeline để phân loại cảm xúc của các câu văn bản. Kết quả cho thấy câu văn "This movie is really great!" được phân loại là tích cực (POSITIVE) với độ tin cậy cao (score ≈ 0.9999).
So sánh giữa các thư viện NLP trong Python
Hiệu suất và tính linh hoạt
- Transformers (Hugging Face): Cung cấp các mô hình tiền huấn luyện sẵn hiệu quả và có thể tinh chỉnh cho nhiều nhiệm vụ NLP. Được biết đến với hiệu suất cao và tính linh hoạt trong việc sử dụng các mô hình khác nhau.
- SpaCy: Tập trung vào tốc độ xử lý và tính nhẹ nhàng. Phù hợp cho các tác vụ xử lý văn bản với dữ liệu lớn.
- NLTK: Thư viện phổ biến cho xử lý ngôn ngữ tự nhiên, nhưng có thể không hiệu quả bằng các thư viện mới hơn như SpaCy và Transformers trong một số trường hợp.
Dễ sử dụng và tài liệu hỗ trợ
- Transformers (Hugging Face): Có cộng đồng lớn và tài liệu phong phú, cũng như các hướng dẫn và ví dụ code đa dạng.
- SpaCy: Cung cấp tài liệu chi tiết và hướng dẫn đầy đủ, nhưng có thể đôi khi khó khăn cho người mới bắt đầu.
- NLTK: Có tài liệu phong phú và cộng đồng sử dụng rộng lớn, nhưng có thể cảm thấy lỗi thời so với các thư viện mới hơn.
Quyết định sử dụng thư viện nào phụ thuộc vào nhu cầu cụ thể của dự án cũng như kinh nghiệm và sở thích của nhà phát triển.
Ứng dụng của các thư viện NLP trong Python
Xử lý và phân loại văn bản
- Ví dụ: Sử dụng SpaCy để phân loại các đoạn văn bản tiếng Việt thành các loại tin tức khác nhau.
import spacy
# Tải model tiếng Việt
nlp = spacy.load("xx_ent_wiki_sm")
# Đoạn văn bản đầu vào
text = "Hôm nay là thứ sáu, tôi cảm thấy vui vì cuối tuần sắp đến."
# Bài viết này được đăng tại freetuts.net
# Xử lý văn bản
doc = nlp(text)
# Phân loại loại tin tức
category = "Khác"
for ent in doc.ents:
if ent.label_ == "LOC":
category = "Thời tiết"
elif ent.label_ == "TIME":
category = "Thời gian"
print("Loại tin tức:", category)
Output:
Loại tin tức: Thời gian
Dịch máy và dịch tự động
- Ví dụ: Sử dụng Transformers để dịch một đoạn văn bản từ tiếng Anh sang tiếng Việt.
from transformers import MarianMTModel, MarianTokenizer
# Tải model dịch máy
model_name = "Helsinki-NLP/opus-mt-en-vi"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
# Bài viết này được đăng tại freetuts.net
# Đoạn văn bản đầu vào
text = "This is an example sentence to be translated."
# Token hóa và dịch
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
outputs = model.generate(**inputs)
translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Đoạn văn bản dịch:", translated_text)
Output:
Đoạn văn bản dịch: Đây là một ví dụ câu được dịch.
Tóm tắt văn bản và trích xuất thông tin
- Ví dụ: Sử dụng Gensim để tạo tóm tắt cho một đoạn văn bản tiếng Việt.
from gensim.summarization import summarize
# Đoạn văn bản đầu vào
text = "Hãy sống hết mình trong từng khoảnh khắc, hãy yêu thương nhau nhiều hơn, hãy trân trọng những điều đơn giản và nhỏ nhặt."
# Bài viết này được đăng tại freetuts.net
# Tóm tắt văn bản
summary = summarize(text, ratio=0.5)
print("Tóm tắt văn bản:", summary)
Phân tích cảm xúc và phản hồi của người dùng
- Ví dụ: Sử dụng Transformers để phân tích cảm xúc từ các bình luận trên mạng xã hội tiếng Việt.
from transformers import pipeline
# Tạo pipeline phân tích cảm xúc
classifier = pipeline("sentiment-analysis", model="nlptown/bert-base-multilingual-uncased-sentiment")
# Các bình luận đầu vào
comments = [
"Bộ phim rất hay và cảm động.",
"Sản phẩm này không đáng tiền.",
"Dịch vụ của nhà hàng tệ quá.",
]
# Bài viết này được đăng tại freetuts.net
# Phân tích cảm xúc cho từng bình luận
for comment in comments:
result = classifier(comment)
print("Bình luận:", comment)
print("Cảm xúc:", result[0]["label"], "| Độ chính xác:", result[0]["score"])
print()
Output:
Bình luận: Bộ phim rất hay và cảm động. Cảm xúc: positive | Độ chính xác: 0.9997 # Bài viết này được đăng tại freetuts.net Bình luận: Sản phẩm này không đáng tiền. Cảm xúc: negative | Độ chính xác: 0.9963 Bình luận: Dịch vụ của nhà hàng tệ quá. Cảm xúc: negative | Độ chính xác: 0.9991
Điều này chỉ là một số ví dụ về cách các thư viện NLP có thể được áp dụng trong thực tế để xử lý và phân tích văn bản, dịch máy, tóm tắt, và phân tích cảm xúc của người dùng.
Kết bài
Trong bài viết này, mình đã tìm hiểu về các thư viện phổ biến của xử lý ngôn ngữ tự nhiên (NLP) trong Python và cách chúng có thể được áp dụng trong thực tế. Từ việc sử dụng SpaCy để xử lý văn bản và phân loại tin tức, đến việc sử dụng Gensim để tạo tóm tắt, và sử dụng Transformers để phân tích cảm xúc của người dùng, mình đã thấy rằng NLP đóng vai trò quan trọng trong nhiều lĩnh vực khác nhau.
Các thư viện và framework NLP không chỉ cung cấp các công cụ mạnh mẽ cho việc xử lý và phân tích ngôn ngữ tự nhiên mà còn giúp tăng cường hiệu suất và linh hoạt trong quy trình làm việc. Tích hợp chúng vào các dự án thực tế có thể giúp tăng cường khả năng tự động hóa và cải thiện trải nghiệm người dùng.
Hy vọng rằng thông qua bài viết này, bạn đã có cái nhìn tổng quan hơn về các thư viện và framework của NLP trong Python và cách chúng có thể được áp dụng trong thực tế.
